מה זה GEO?
GEO = Generative Engine Optimization. המושג מתייחס לאופטימיזציה למנועים גנרטיביים – אסטרטגיה חדשה בתחום השיווק הדיגיטלי המתמקדת בשיפור הנראות של תוכן באמצעות מנועי חיפוש מבוססי בינה מלאכותית גנרטיבית, כמו ChatGPT, Google Gemini או Perplexity.
בניגוד ל-SEO המסורתי שמתמקד בדירוג אתרים בתוצאות חיפוש קלאסיות, GEO שמה דגש על יצירת תוכן עשיר בהקשר, מדויק ומבוסס נתונים, שיאפשר למודלי AI "להבין" אותו טוב יותר ולהשתמש בו כמקור אמין בתשובות שהם מייצרים ישירות למשתמשים. לכן, בעידן שבו חיפושים הופכים לשיחות טבעיות ותשובות מידיות ומותאמות אישית, GEO הוא כלי הכרחי עבור כל מנהל שיווק דיגיטלי.
מה המשמעות של "מנועים" ושל "גנרטיביים" בהגדרה שלעיל?
מנועים גנרטיביים הם מערכות בינה מלאכותית מתקדמות, כמו ChatGPT או Google Gemini, שמכונות "מנועים" משום שהן פועלות כמו מכונות חכמות לעיבוד וניתוח מידע, בדומה למנועי חיפוש מסורתיים, אך עם יכולות משופרות. המונח "גנרטיביים" הוא עברות של המילה Generate שמשמעותה "לייצר" והוא מתייחס ליכולתם של המנועים האלה ליצור תוכן חדש: טקסט, תמונות או תשובות מותאמות אישית – באופן עצמאי, על בסיס נתונים ודפוסים שהם למדו ממאגרי מידע עצומים.
בניגוד למנועי חיפוש קלאסיים שמציגים רשימת קישורים, מנועים גנרטיביים מספקים תשובות ישירות, מובנות ומותאמות לשאילתות בשפה טבעית, תוך שימוש בהבנת הקשר ו"חשיבה" יצירתית. לדוגמה, כאשר משתמש שואל שאלה מורכבת, המנוע הגנרטיבי לא רק מוצא עבורו מידע, אלא גם מסנתז אותו לתגובה קוהרנטית ורלוונטית.
אופן חיפוש המידע עובר מהפכה
להבדיל מהקישורים שמספק מנוע חיפוש מסורתי, המובילים אותנו לעמוד באתר אינטרנט, מנועים גנרטיביים רוצים להשאיר אותנו בתוך הצ'אט ולספק לנו בתוכן את כל המידע. אם עד היום המטרה של אתרי אינטרנט הייתה להעניק לנו, הגולשים, מידע, בעידן ה-GEO המטרה של המידע באתר הוא להעשיר את הדאטה בייס של מנועים גנרטיביים כמו Chat GPT ולהוות מרכיב בתשובות שהם מספקים לנו.
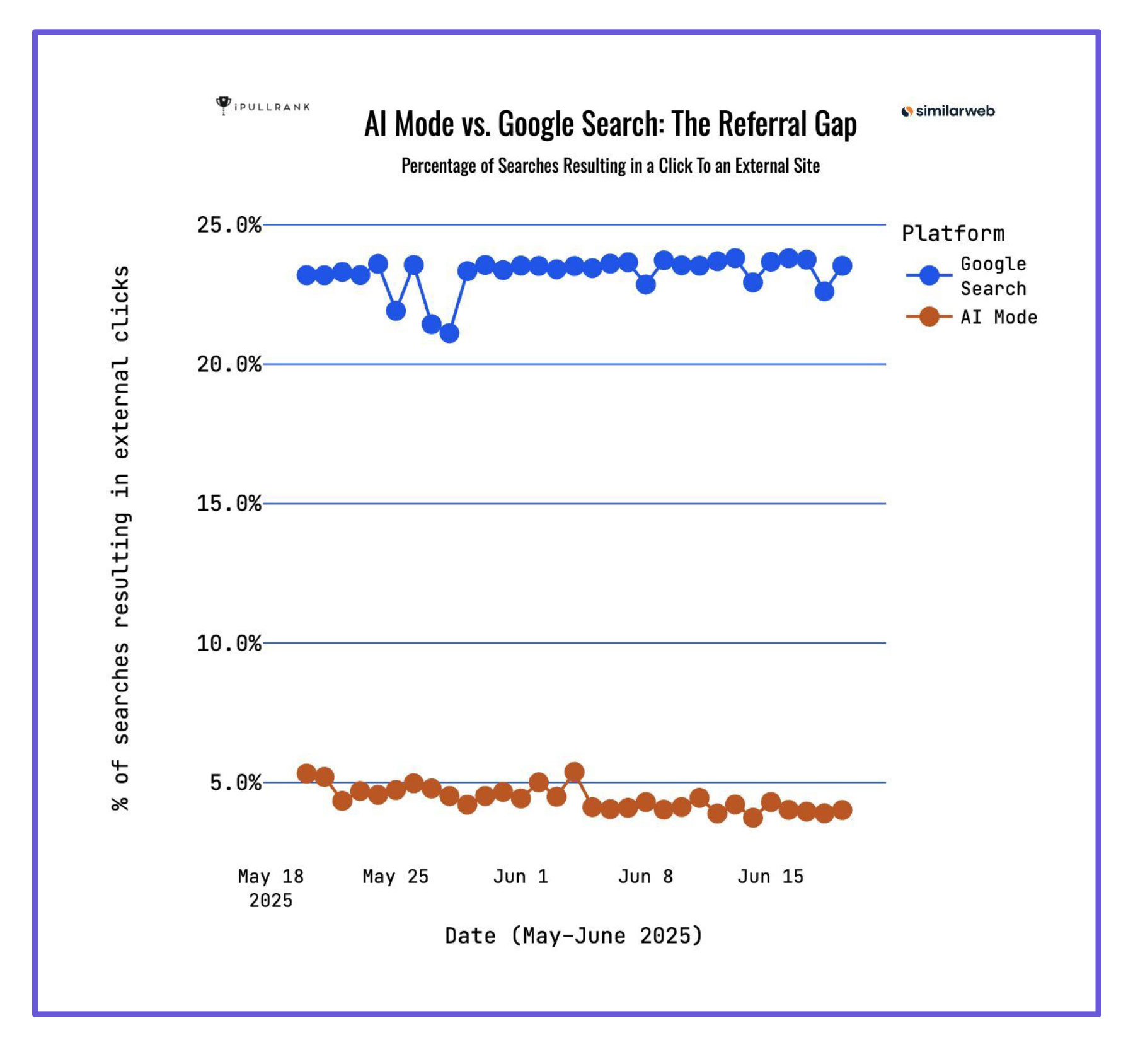
בהשוואה ל-25% הקלקה מסך החיפושים בגוגל, רק 5% מסך החיפושים ב-AI מסתיימים בקליק על קישור:
צ'אטבוטים מובילים בתחום הבינה המלאכותית הגנרטיבית לפי נתח שוק – אוגוסט 2025 בארה"ב
כאנשי שיווק, חשוב מאד שלא נייחס משקל יתר לצ'אטבוט המועדף על ידינו – אנחנו צריכים לבצע אופטימיזציה שמותאמת לצ'אטבוטים הפופולאריים ביותר. היות ו-ChatGPT מובילה בפער משמעותי על שאר המתחרים, אנחנו קודם כל צריכים לבצע אופטימיזציה ל-ChatGPT:
| צ'אטבוט | נתח שוק מתוך חיפושי Ai | הערכה של צמיחה רבעונית | |
|---|---|---|---|
| 1 | ChatGPT | 60.60% | 7% |
| 2 | Microsoft Copilot | 14.10% | 6% |
| 3 | Google Gemini | 13.40% | 8% |
| 4 | Perplexity | 6.50% | 13% |
| 5 | Claude AI | 3.50% | 14% |
מקור: Top Generative AI Chatbots by Market Share – September 2025
האפליקציות שהורדו הכי הרבה בחודש יולי 2025
| דירוג | iOS App Store | Google Play | סה"כ |
|---|---|---|---|
| 1 | ChatGPT (14M) | ChatGPT (38M) | ChatGPT (52M) |
| 2 | Threads (11M) | TikTok Lite (32M) | TikTok (39M) |
| 3 | CapCut (10M) | Instagram (31M) | Instagram (38M) |
| 4 | Google Maps (10M) | Facebook (25M) | Facebook (30M) |
| 5 | Temu (9M) | WhatsApp (21M) | WhatsApp (27M) |
| 6 | Google (9M) | Temu (17M) | Temu (26M) |
| 7 | TikTok (8M) | Snapchat (16M) | CapCut (23M) |
| 8 | Instagram (6M) | Telegram (14M) | Threads (23M) |
| 9 | Telegram (6M) | WhatsApp Business (13M) | Telegram (20M) |
| 10 | SHEIN (6M) | CapCut (13M) | Snapchat (20M) |
מקור: ChatGPT Leads Downloads While TikTok Stays on Top in Revenue for July
כבר היום 12% מהחיפושים מבוצעים באמצעות GenAi וההערכה היא שבשנת 2028 50% מהחיפושים יבוצעו באמצעות GenAi. אנשי שיווק ואנשי SEO צריכים לבצע אופטימיזציה של התוכן באתרים שהם מקדמים לא רק עבור בני אדם, אלא גם עבור בוטים של מנועי חיפוש מבוססי GenAi.
איך ChatGPT עובד מאחורי הקלעים?
שלב 1: המשתמש כותב פרומט
התהליך מתחיל כשמשתמש ב-ChatGPT כותב פרומפט. לדוגמה: “מהם היתרונות של טיפול מורפיאוס 8 וכמה זמן נמשכת ההחלמה?”. המערכת מקבלת את זה הפרומפט הזה כטקסט גולמי ומתחילה את שרשרת העיבוד.
שלב 2: עיבוד ראשוני של הפרומפט
בשלב זה מבוצעות הפעולות הבאות:
- Tokenization: הטקסט מחולק ליחידות קטנות (tokens) שהמודל מבין.
- Context Building: המערכת יוצרת Context Window (חלון הקשר בתרגום חופשי) שכולל את הפרומפט, השיחות הקודמות והזיכרון הקבוע של המשתמש (אם Memory מופעל). נסביר בהמשך מה המשמעות של Memory בהקשר הזה.
- Classification: המערכת מזהה את סוג הבקשה:
- האם זו שאלה שמטרתה לקבל מידע עובדתי קיים (knowledge-based question או factual query)?
- האם נדרש מידע מהאינטרנט כדי לענות לשאלה?
- האם יש תוכן אישי שהמערכת כבר מכירה לגביך שרלוונטי להרכבת התשובה?
מה המשמעות של Memory?
Memory הוא מנגנון שמאפשר ל-LLM לזכור מידע על המשתמש או על אינטראקציות קודמות שלו לאורך זמן.
שלב 3: שילוב היכולות – LLM, RAG ו-Memory
כדי לענות תשובות חכמות, מדויקות ומעודכנות, המערכת לא מסתמכת רק על מנוע השפה שלה. היא בנויה משלוש שכבות שונות שכל אחת מהן נועדה לפתור מגבלה אחרת של הבינה המלאכותית.
שכבה ראשונה: LLM (Large Language Model) – המנוע עצמו או "המוח"
LLM היא השכבה הבסיסית והמרכזית. LLM או מודל השפה הגדול (Large Language Model) הוא המודל האחראי להבין טקסטים, לנתח הקשרים וליצור תשובות חדשות בצורה טבעית. הוא יודע "לחשוב" אבל הוא לא יודע לחפש ידע חדש – כל הידע שלו נלמד מראש בזמן האימון ולכן הוא מוגבל לידע שצבר או שהיה קיים עד לתאריך מסוים.
מה ה-LLM עושה:
- ה-LLM אומן מראש על כמויות עצומות של טקסטים כדי להבין וליצור שפה אנושית.
- הוא יודע לענות, לנסח, לתרגם, לכתוב קוד, ליצור סיכומים וכו'.
- אין לו גישה בזמן אמת למידע חיצוני (אלא אם מחברים אליו כלים כמו web search או RAG).
- אין לו זיכרון מתמשך – הוא לא "זוכר" שיחות קודמות מעצמו.
לדוגמה: אם נשאל "מה זה RAG?", מודל כמו GPT-5 יספק לנו הסבר לפי הידע שנאגר באימון שלו עד יוני 2024 – גם ללא צורך בחיפוש באינטרנט.
שכבה שניה: RAG (Retrieval-Augmented Generation) – שילוב עם מאגר ידע
RAG הוא שכבת תוספת מעל ה-LLM שמאפשרת לו לשלוף מידע בזמן אמת ממקור חיצוני (Knowledge Base, מסמכים, אינטרנט וכו'). השכבה הזו נוצרה כדי להתגבר על המגבלה המרכזית של ה-LLM: חוסר היכולת לגשת למידע חדש או למקורות ידע פרטיים. RAG מאפשרת למודל לשלוף בזמן אמת מידע רלוונטי ממסמכים, מאגרי נתונים או מהאינטרנט ולשלב אותו בתוך התשובה כאילו היה חלק מהידע הפנימי שלו.
RAG קיימת כדי לאפשר למערכת לענות על שאלות מבוססות עובדות עדכניות כגון נתונים עסקיים, מסמכים ארגוניים או תכנים מאתרי אינטרנט.
איך ה-RAG עובד:
- המשתמש שואל שאלה.
- המערכת מחפשת (Retrieval) מסמכים רלוונטיים ממאגר ידע (או מאתרים ברשת).
- המסמכים נשלפים ומוזרקים לשאילתה שהולכת למודל.
- המודל יוצר תשובה (Generation) שמשתמשת בתוכן שנשלף.
לדוגמה: אם נשאל "מה מדיניות ההחזר של חברת אבי אלקטרוניקה?" RAG ישלוף את העמוד מהאתר של אבי אלקטרוניקה וייתן תשובה מדויקת מתוך המידע הרלוונטי.
שכבה שלישית: Memory – שכבת הזיכרון האישי והמתמשך
Memory הוא מנגנון שמאפשר ל-LLM לזכור מידע על המשתמש או על אינטראקציות קודמות לאורך זמן: מי אתה, מה אתה עושה, על אילו פרויקטים דיברת עם ChatGPT או כל מנוע אחר ואיך אתה מעדיף לעבוד. היא לא מיועדת לשלוף ידע כללי מהעולם, אלא להבין אותך כפרט ולשמור על קשר מתמשך. השכבה הזו קיימת כדי לאפשר אינטראקציה מתמשכת ואישית כך שהמערכת תוכל לענות בהקשר של מה שנכתב בעבר בינך לבין המערכת ולהפוך לעוזר שמכיר אותך ואת סגנון העבודה שלך.
מה ה-Memory עושה:
- שומר עובדות שהוא כבר יודע עליך. לדוגמה: המשתמש מקדם אתרים, הוא מקדם את האתר seo-guide.co.il וכדומה.
- יכול להשתמש בעובדות שהוא מכיר בשיחות עתידיות – גם אם מדובר בצ’אט חדש.
- מאפשר קיום של שיח מתמשך ואישי כמו של עוזר אישי שכבר מכיר אותך.
היתרון של ה-Memory שהוא מאפשר יחס מותאם אישית ויעילות לאורך. החיסרון שלו הוא שהוא לא מיועד לשמירת מסמכים או עובדות גדולות, אלא רק לשמירת פרטים חשובים אודות המשתמש.
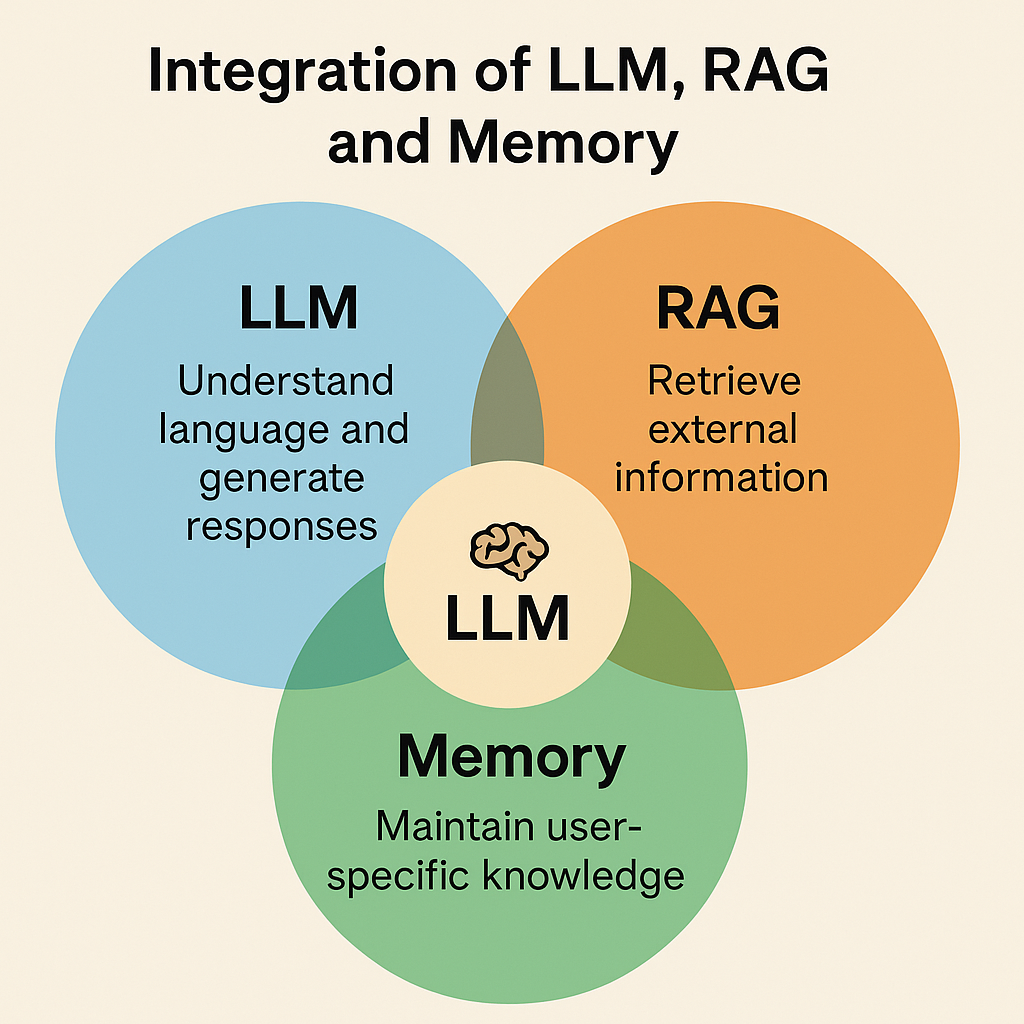
סיכום הפעולות של שלושת השכבות לאחר כתיבת פרומפט על ידי הגולש
- LLM (Large Language Model): המנוע המרכזי. הוא משתמש בידע שלו מהאימון כדי להבין את השפה ולהרכיב את התשובה. אם המידע הדרוש נמצא כבר בידע שלו – הוא עונה מיד. אם לא, הוא "מבקש עזרה" מהשכבות הנוספות.
- RAG (Retrieval-Augmented Generation): אם המערכת מזהה צורך במידע עדכני (כמו מחירים, אתרי אינטרנט או מסמכים פנימיים) היא שולחת את השאילתה למנוע אחזור מידע. מנוע זה מחפש מקורות רלוונטיים (למשל דף באתר אינטרנט שהמערכת יודעת לקשר אליך או מסמך PDF שהעלית). המנוע מחזיר למודל קטעי טקסט רלוונטיים בלבד (Contextual Snippets). המודל קורא אותם ומשלב אותם בתשובה שלו.
- Memory (זיכרון אישי ומתמשך): לפני שהתשובה נוצרת, המערכת בודקת אם יש פרטים קודמים עליך שיכולים לשפר את התשובה. לדוגמה: "המשתמש הוא מקדם אתרים" או "המשתמש מקדם את האתר seo-guide.co.il". אם הוא מוצא מידע כזה הו מצורף לשאילתה בצורה סמויה (לא כחלק מהשאלה שלך, אלא בתור "context metadata"). כך המודל מסוגל לייצר מענה בהתאמה אישית (למשל: לכלול המלצות רלוונטיות לאתרי קידום אתרים, כי הוא "זוכר" שזה התחום שלך).
- יצירת תשובה (Generation): לאחר שכל המידע נאסף המודל מריץ רשת נוירונים שחוזה מילה אחרי מילה את התשובה הטובה ביותר. התשובה נוצרת באופן הסתברותי (לא בשליפה מדויקת ממסד נתונים). המערכת בוחנת טונאליות, סגנון והקשר כדי ליצור ניסוח טבעי.
- הצגת התשובה: המערכת מציגה את התשובה על המסך, לעיתים עם הפניות (אם נשלפו מקורות מ-RAG) או עם תוספות חזותיות (טבלאות, גרפים, תמונות). אם המערכת תומכת בזיכרון, חלק מהמידע החדש יכול להישמר להמשך השיחות שלך לדוגמה: אם תכתוב "זכור ש-SEO-GUIDE זה אתר שלי", המידע הזה יישמר ב-Memory.
| שכבה | תפקיד | מידע שהיא שואבת | נשמר לאורך זמן? |
|---|---|---|---|
| LLM | הבנת שפה ויצירת טקסט | מאימון המודל | ❌ |
| RAG | חיבור למידע חיצוני בזמן אמת | מסמכים, אתרים, מאגרי ידע | ❌ |
| Memory | שמירה של ידע אישי על המשתמש | פרטי משתמש, שיחות קודמות | ✅ |
Transformer Neural Network – הארכיטקטורה שמאחורי כל LLM מודרני
רשת נוירונים מלאכותית (Neural Network) היא מערכת מתמטית שמדמה במידה מסוימת את דרך הפעולה של המוח האנושי: היא מורכבת מנוירונים מלאכותיים שהן למעשה יחידות חישוב פשוטות. כל נוירון מקבל קלט (input), שוקל אותו לפי משקל (weight), מוסיף הטיה (bias) ומעביר את התוצאה דרך פונקציית הפעלה (activation).
התוצאה מועברת לשכבות הבאות של נוירונים, עד שמתקבלת פלט סופי. במקרה של מודל שפה, הפלט הסופי הוא המילה הבאה הצפויה ביותר במשפט.
מה מייחד את ה-Transformer Neural Network?
מודלים כמו GPT, Claude, Gemini ו-LLaMA (Large Language Model Meta AI) מבוססים על ארכיטקטורה שנקראת Transformer. ה-Transformer מורכב ממאות מיליארדי נוירונים מאורגנים בשכבות (layers) והוא נועד להתמודד עם רצפים של מילים (sequence modeling) – כמו בשפה טבעית.
איך רשת Transformer פועלת בפועל
נניח שהמשתמש כתב: "מה היתרונות של טיפול מורפיאוס 8?" – הרשת תעבור את התהליך הבא:
- Tokenization – המשפט מפורק ל-tokens (יחידות לשוניות קטנות – מילים או חלקי מילים). למשל: ["מה", "היתרונות", "של", "טיפול", "מורפיאוס", "8", "?"].
- Embedding – כל token מומר לווקטור מספרי (מערך של מאות או אלפי מספרים) המייצג את משמעותו. כך נוצרת מפה מתמטית של משמעות מילולית.
- Positional Encoding – היות והרשת לא יודעת מה סדר המילים הנכון מעצמה, מוסיפים קואורדינטות מיקום – מספרים שמייצגים את המיקום היחסי של כל מילה במשפט. השלב הזה מאפשר למודל להבין את ההבדל בין "החתול רדף אחרי הכלב" ל"הכלב רדף אחרי החתול".
- Self-Attention – זהו הלב של ה-Transformer. במקום לעבד כל מילה בנפרד, המודל מחשב עד כמה כל מילה קשורה לכל מילה אחרת במשפט. כל מילה "שמה לב" (attends) למילים אחרות. למשל, בשאלה לעיל המילה "יתרונות" תתמקד במילים "מורפיאוס 8" כדי להבין על מה מדובר. המודל מחשב מטריצה של קשרים (attention weights) בין כל זוג מילים כדי לבנות הקשר עמוק – להבין משמעות, לא רק תחביר.
- Feed-Forward Layers – לאחר חישובי ה-attention התוצאה עוברת שכבות נוירונים "רגילות" שממפות את המשמעות למרחב מופשט יותר. זה קורה מאות פעמים: כל שכבה "מבינה" טוב יותר את הקשרים בין מילים.
- Prediction – ניבוי המילה הבאה – לבסוף, המודל מנבא את ההסתברות של כל מילה אפשרית שתבוא אחרונה: "הטיפול", "נחשב", "יעיל", "מאוד", "ב…" וכו'. הוא בוחר את המילה בעלת ההסתברות הגבוהה ביותר (או משלב בין כמה באמצעות sampling) ואז חוזר שוב כדי לנבא את המילה שאחריה. כך נוצר המשפט מילה אחרי מילה בזמן אמת.
בזמן האימון המודל נחשף למאות מיליארדי משפטים. בכל שלב הוא לומד לנבא את המילה הבאה לפי ההקשר שקדם לה. אם לדוגמה המשפט הנכון הוא "חומצה היאלורונית משמשת למילוי קמטים" והמודל ניבא "חומצה היאלורונית משמשת לשתייה" הוא יקבל "עונש" מתמטי (שגיאה) ויעדכן את המשקלים הפנימיים שלו (weights) כך שיצמצם את האפשרות לטעות בפעם הבאה. מיליארדי תיקונים כאלה יוצרים בסופו של דבר את הבנת השפה של המודל. המודל בעצם לא "יודע" עברית או אנגלית – הוא מחשב הסתברויות על סמך דפוסים מתמטיים שנלמדו מאינספור טקסטים.
המעבר ממילות מפתח לפרומפטינג (Prompting)
להבדיל מקידום אורגני, שבו אנחנו מבצעים אופטימיזציה לתוכן ולמבנה האתר על בסיס מילות מפתח, ב-GEO אנחנו צריכים לבצע אופטימיזציה שמבוססת על פרומפטים. האתגר הוא, שבשעה שיש לנו הרבה מאד כלים שמסייעים לנו להחליט באילו מילות מפתח להתמקד (Ahrefs, Semrush, People also ask, Google ads ועוד), אין לנו (כרגע) כלי טוב שיסייע לנו להחליט לאילו פרומפטים אנחנו מבצעים אופטימיזציה (ואיך).
כיצד מחליטים לאילו פרומפטים לבצע אופטימיזציה?
- המרת מילות מפתח לפרומפטים: נסו להסיק מהם הפרומפטים שהלקוחות שלכם עשויים לכתוב, על בסיס מילות מפתח שאתם יודעים שרלוונטיות לתחום העיסוק שלכם. אתם יכולים להשתמש במילות מפתח שאתם משתמשים בהם לקידום ומידע מ-Google Search Console ומקמפיינים ב-Google Ads. כשאתם מחפשים רעיונות חפשו שאלות שגולשים שאלו, היות ושאלות קרובות יותר לפרומפטים מאשר מילות מפתח.
- שימוש בידע שקיים בארגון – שאלות שלקוחות ולקוחות פוטנציאליים של הארגון שואלים את אנשי המכירות.
- השתמשו בשאלות שעולות בחשבונות פייסבוק ואינסטגרם שאתם מנהלים – בתגובות בפוסטים, ב-DM ועוד.
אתם צריכים להשתמש במילות המפתח כדי להגדיר שאלות שטבעי שגולשים ישאלו ואת השאלות לרכז לקבוצות שמתמקדות בכוונה של הגולש.
הגעתי לכאן: Session#2
איך לוודא שהאתר שלכם מדורג גבוהה ב-AI Overview?
לפי ahrefs אלה הצעדים שאתם צריכים לבצע:
- טרגטו מילות מפתח בעלות זנב ארוך (Long tail keywords): הסיכוי של התוכן שלכם להופיע ב-AI Overview גדול יותר אם התוכן שלכם יכיל מילות מפתח בעלות זנב ארוך בנות 4 מילים ויותר, בהשוואה ל-2 מילים בתוצאות ה"רגילות" שאינן תוצאות AI.
- טרגטו מילות מפתח שיחסית קל יותר לקדם: מחקר שבוצע ע"י ahrefs מצא ש-71% ממילות המפתח שמופיעות בתוכן שמוצג ב-AI Overview הוא ברמת קושי של מתחת ל-30 (KPI פנימי של ahrefs) כאשר הממוצע הוא 12, בהשוואה ל-33 עבור תוצאות רגילות. יש לכך השלכה גם על כמות הקישורים שתצטרכו, לפי תוצאות המחקר, כדי לקדם מילות מפתח עבור AIO.
- נסו להתאים את התוכן שאתם יוצרים לצורך של הגולשים: המחקר של ahrefs מראה ש-99.2% ממילות המפתח ב-AIO קשורות לאינפורמציה: פרטים, הסברים והדרכה.
- בצעו אופטימיזציה של התוכן ל-Featured Snippets ול-People Also Aske. יש לשים לב ש-Featured Snippets מתעדפים התאמה מדוייקת למילת המפתח ו-AIO מתעדפים Search Intent.
- שפרו את הנראות והנוכחות של המותג שלכם ברשת: מידע והמלצות אודות המותג שלכם עשוי להופיע במקורות נוספות ברחבי הרשת, לא רק באתר שלכם.
- זהו עבור אילו פרומפטים המתחרים שלכם מופיעים ב-AIO:
תכנים שנגישים ל-ChatGPT באמצעות Bing ברשתות החברתיות
סוגי תכנים נגישים:
- פוסטים ציבוריים בלבד של עמודים או קבוצות פתוחות שנסרקו על ידי Bing.
- עמודי עסקים, עמותות או קליניקות, כולל טקסט, תמונות ותיאורי פוסטים (אם הם ציבוריים).
סוגי תכנים שאינם נגישים:
- פוסטים מחשבונות אישיים.
- תגובות, תגיות או הודעות פרטיות.
- תוכן שאינו מאונדקס (כמעט כל מה שדורש התחברות לפייסבוק).
סוגי תכנים נגישים:
- דפי פרופיל ציבוריים ועמודי מותגים שנסרקו על ידי Bing.
- טקסט מתיאורי פוסטים (Captions) אם הם מופיעים באינדקס של Bing.
סוגי תכנים שאינם נגישים:
- פוסטים שאינם מאונדקסים (רוב התמונות והסטוריז לא מאונדקסים כלל).
- תגובות, לייקים או Reels, אלא אם כן מישהו פרסם קישור ישיר אליהם באתר אחר.
- מידע בזמן אמת (אין חיבור ישיר ל-Meta של API).
YouTube
סוגי תכנים נגישים:
- תיאורי סרטונים, תגיות, כותרות ותגובות פומביות ש-Bing אינדקס.
- לעיתים גם סיכומי תוכן מתוך עמוד הסרטון (דרך Open Graph metadata).
סוגי תכנים שאינם נגישים:
- צפייה או ניתוח של הווידאו עצמו (ChatGPT לא "רואה" וידאו).
- תגובות לא מאונדקסות או תוכן מוסתר.
X (לשעבר Twitter)
סוגי תכנים נגישים:
- ציוצים ציבוריים ש-Bing או אתרים אחרים (כמו Thread Reader) אינדקסו.
- עמודים של ארגונים, מותגים ואישים ציבוריים.
סוגי תכנים שאינם נגישים:
- ציוצים בזמן אמת או תוכן מתוך פיד חי.
- תגובות, DM או תוכן מוגבל גישה.
סוגי תכנים נגישים:
- עמודי חברות ציבוריים (תיאור חברה, כתובת, תעשייה וכו').
- מאמרים (LinkedIn Articles) שפתוחים לגישה ציבורית.
סוגי תכנים שאינם נגישים:
- פוסטים רגילים בפיד (כמעט תמיד דורשים התחברות).
- פרופילים אישיים או הודעות.
TikTok
סוגי תכנים נגישים:
- תיאורים של סרטונים (Captions) בעמודי צפייה פומביים שנסרקו ע"י Bing.
- פרופילים ציבוריים במידה והם מופיעים באינדקס.
סוגי תכנים שאינם נגישים:
- הווידאו עצמו.
- תגובות, לייקים או צפיות בזמן אמת.
- תוכן שאינו מאונדקס או דורש התחברות.
שאלות ותשובות
ChatGPT משתמש נכון להיום במנוע החיפוש Bing של Microsoft לצורך ביצוע חיפושים בזמן אמת. אם אתם רואים ש-ChatGPT משתמש בכלי ה-web (לדוגמה: “מחפש ברשת”), בפועל החיפוש מתבצע דרך Bing Search API.
כש-ChatGPT מבצע חיפוש ברשת באמצעות הכלי web, הוא ניגש למקורות שנגישים לציבור דרך מנוע החיפוש Bing. אם תוכן מרשת חברתית כמו פוסט בטוויטר/X, פוסט ציבורי בפייסבוק, סרטון ביוטיוב, פוסט בלינקדאין או פוסט באינסטגרם מופיע באינדוקס של מנוע החיפוש, ChatGPT יכול לגשת אליו (אם הוא כאמור ציבורי), לקרוא אותו ולהשתמש במידע שבו כחלק מהתשובה.
עם זאת, יש למידע מהרשתות החברתיות מגבלות ברורות:
אין ל-ChatGPT גישה ישירה לממשקי הרשתות החברתיות (API's) של Meta, X, TikTok וכו'.
ChatGPT לא “גולש” בתוך הרשתות או רואה תוכן פרטי, תגובות או פוסטים שאינם מאונדקסים במנועי חיפוש.
ChatGPT לא שואב מידע בזמן אמת מתוך הפידים של משתמשים או מעמודים פרטיים.